Data Structures Write Up
this is the writeup for my data structures project
Collections
Log Python Model code and SQLite Database
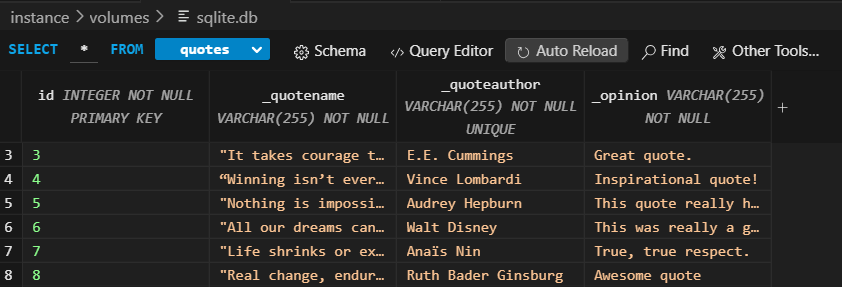
In the image above, the following rows are displayed:
- quotename: The quote itself
- quoteauthor: The author of the corresponding quote
- opinion: Opinions/Thoughts on the corresponding quote
Quotes database code
from random import randrange
from datetime import date
import os, base64
import json
from __init__ import app, db
from sqlalchemy.exc import IntegrityError
from werkzeug.security import generate_password_hash, check_password_hash
class Quote(db.Model):
__tablename__ = 'quotes' # table name is plural, class name is singular
# Define the User schema with "vars" from object
id = db.Column(db.Integer, primary_key=True)
_quotename = db.Column(db.String(255), unique=False, nullable=False)
_quoteauthor = db.Column(db.String(255), unique=False, nullable=False)
_opinion = db.Column(db.String(255), unique=False, nullable=False)
# Defines a relationship between User record and Notes table, one-to-many (one user to many notes)
# constructor of a User object, initializes the instance variables within object (self)
def __init__(self, quotename, quoteauthor, opinion):
self._quotename = quotename # variables with self prefix become part of the object,
self._quoteauthor = quoteauthor
self._opinion = opinion
@property
def quotename(self):
return self._quotename
@quotename.setter
def quotename(self, quotename):
self._quotename = quotename
@property
def quoteauthor(self):
return self.quoteauthor
@quoteauthor.setter
def quoteauthor(self, quoteauthor):
self._quoteauthor = quoteauthor
@property
def opinion(self):
return self._opinion
@opinion.setter
def opinion(self, opinion):
self._opinion = opinion
def __str__(self):
return json.dumps(self.read())
def create(self):
try:
# creates a person object from User(db.Model) class, passes initializers
db.session.add(self) # add prepares to persist person object to Users table
db.session.commit() # SqlAlchemy "unit of work pattern" requires a manual commit
return self
except IntegrityError:
db.session.remove()
return None
def read(self):
return {
"id": self.id,
"quotename": self.quotename,
"quoteauthor": self.quoteauthor,
"opinion": self.opinion
}
Quote Initialization Code (Testing Quote Data):
# Builds working data for testing
def initQuotes():
with app.app_context():
"""Create database and tables"""
db.create_all()
"""Tester data for table"""
quotes = [
Quote(quotename="It takes courage to grow up and become who you really are.", quoteauthor="E.E. Cummings", opinion="Great quote."),
Quote(quotename="Winning isn’t everything, but wanting to win is.", quoteauthor="Vince Lombardi", opinion="Inspirational quote!"),
Quote(quotename="Nothing is impossible. The word itself says 'I'm possible!'", quoteauthor="Audrey Hepburn", opinion="This quote really hit."),
Quote(quotename="All our dreams can come true, if we have the courage to pursue them.", quoteauthor="Walt Disney", opinion="This was really a good quote.")
]
"""Builds sample user/note(s) data"""
for quote in quotes:
try:
quote.create()
except IntegrityError:
'''fails with bad or duplicate data'''
db.session.remove()
print(f"Records exist, duplicate email, or error: {quote.quoteauthor}")
Lists and Dictionaries
Blog Python API code and use of List and Dictionaries.
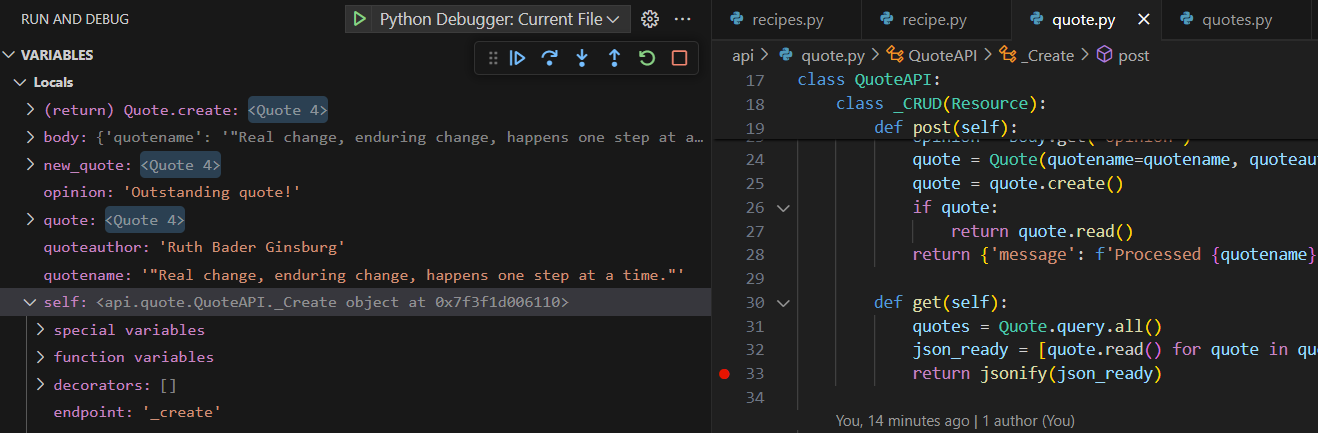
The screenshot above shows the quote build using POST
Both screenshots show the variables – extracted from database as Python objects
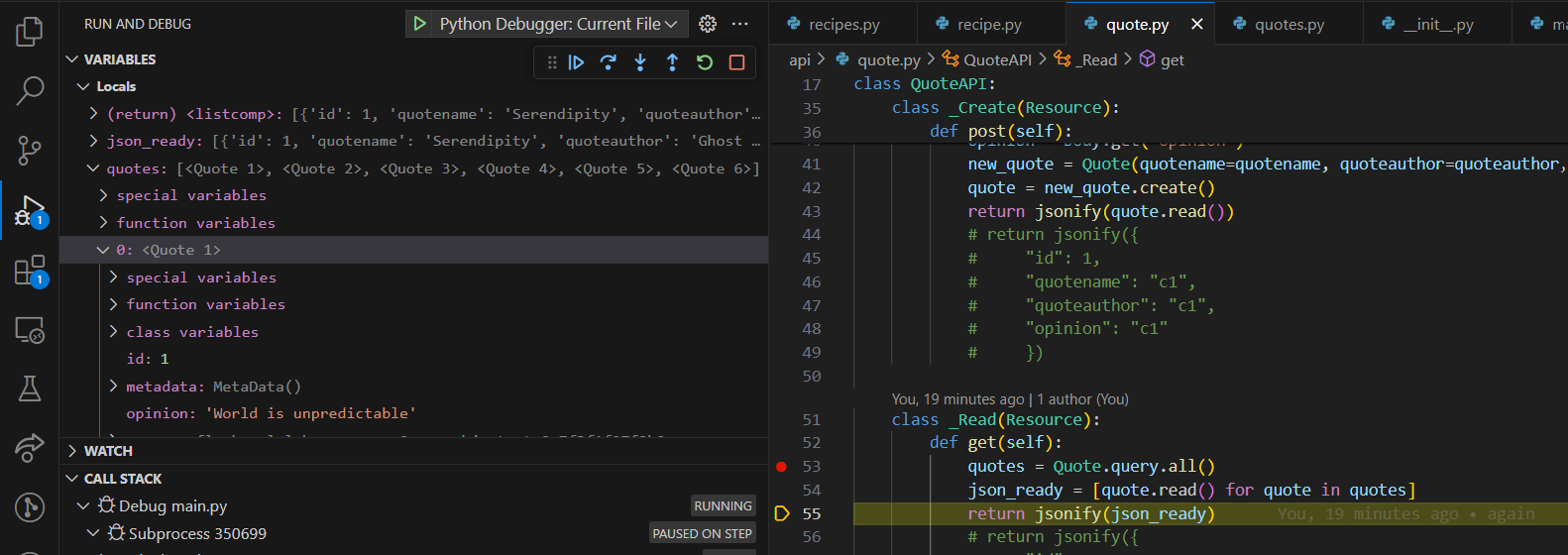
The screenshot above shows the quote read list using GET Frontend code fetches data from quote database and then sends the list of all therapies from database as it is shown above. The list then retusn the information as python objects as displayed in the debugging session.
List named quote> this holds all the python objects such as quote1,quote2,quote3,etc.
 This is the API code which can be used to fetch data from backend
I used the “quote.query.all()” which gets all the quotes from the database
This is the API code which can be used to fetch data from backend
I used the “quote.query.all()” which gets all the quotes from the database
 This shows the variables and the GET fetching variables– quotename,quoteauthor,opinion
This shows the variables and the GET fetching variables– quotename,quoteauthor,opinion
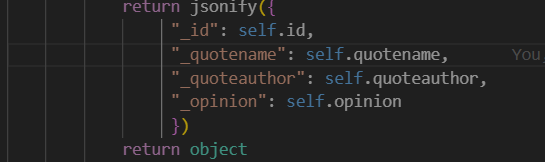 Therapy Model Dictionary– stored in backend, values of the keys are on the right
Read in quote database returns the quote data
Therapy Model Dictionary– stored in backend, values of the keys are on the right
Read in quote database returns the quote data
APIs and JSON
Blog Python API code and use of Postman to request and respond with JSON.
In VSCode, show Python API code definition for request and response using GET, POST, UPDATE methods. Discuss algorithmic condition used to direct request to appropriate Python method based on request method.
Below, I have shown the code for the quotes API that I used. The API code is so we can use/deal with GET and POST requests from the frontend for the quote inputs. Get()/post() functions in the code are responsible for handling the response to the frontend requests.
API for Quote-Repository
""" database dependencies to support sqliteDB examples """
from random import randrange
from datetime import date
import os, base64
import json
from __init__ import app, db
from sqlalchemy.exc import IntegrityError
from werkzeug.security import generate_password_hash, check_password_hash
class Quote(db.Model):
__tablename__ = 'quotes' # table name is plural, class name is singular
# Define the User schema with "vars" from object
id = db.Column(db.Integer, primary_key=True)
_quotename = db.Column(db.String(255), unique=False, nullable=False)
_quoteauthor = db.Column(db.String(255), unique=False, nullable=False)
_opinion = db.Column(db.String(255), unique=False, nullable=False)
# Defines a relationship between User record and Notes table, one-to-many (one user to many notes)
# constructor of a User object, initializes the instance variables within object (self)
def __init__(self, quotename, quoteauthor, opinion):
self._quotename = quotename # variables with self prefix become part of the object,
self._quoteauthor = quoteauthor
self._opinion = opinion
@property
def quotename(self):
return self._quotename
@quotename.setter
def quotename(self, quotename):
self._quotename = quotename
@property
def quoteauthor(self):
return self.quoteauthor
@quoteauthor.setter
def quoteauthor(self, quoteauthor):
self._quoteauthor = quoteauthor
@property
def opinion(self):
return self._opinion
@opinion.setter
def opinion(self, opinion):
self._opinion = opinion
def __str__(self):
return json.dumps(self.read())
def create(self):
try:
# creates a person object from User(db.Model) class, passes initializers
db.session.add(self) # add prepares to persist person object to Users table
db.session.commit() # SqlAlchemy "unit of work pattern" requires a manual commit
return self
except IntegrityError:
db.session.remove()
return None
def read(self):
return {
"id": self.id,
"quotename": self.quotename,
"quoteauthor": self.quoteauthor,
"opinion": self.opinion
}
Code for Heart API
from flask import Blueprint, jsonify, Flask, request
from flask_cors import CORS # Import CORS
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from flask_restful import Api, Resource
import numpy as np
import json
# Define a blueprint for the heart disease prediction API
heart_api = Blueprint('heart_api', __name__, url_prefix='/api/heart')
api = Api(heart_api)
CORS(heart_api)
class HeartModel:
"""A class representing the Heart Disease Prediction Model."""
# Singleton instance for HeartModel
_instance = None
def __init__(self):
"""Constructor method for HeartModel."""
self.model = None
self.dt = None
self.features = ['sex', 'age', 'cp', 'trtbps', 'chol', 'exng']
self.target = 'output'
# Load the heart disease dataset from a Google Drive link
url = 'https://drive.google.com/file/d/1kJcitXtlysIg1pCPQxV-lMSVTFsLWOkv/view'
url = 'https://drive.google.com/uc?id=' + url.split('/')[-2]
self.heart_data = pd.read_csv(url)
def _clean(self):
"""Clean the dataset and prepare it for training."""
# Drop unnecessary columns from the dataset
self.heart_data.drop(['fbs', 'restecg', 'thalachh', 'oldpeak'], axis=1, inplace=True)
# Drop rows with missing values
self.heart_data.dropna(inplace=True)
def _train(self):
"""Train the logistic regression and decision tree models."""
# Split the dataset into features (X) and target (y)
X = self.heart_data[self.features]
y = self.heart_data[self.target]
# Initialize and train the logistic regression model
self.model = LogisticRegression(max_iter=1000)
self.model.fit(X, y)
# Initialize and train the decision tree classifier
self.dt = DecisionTreeClassifier()
self.dt.fit(X, y)
@classmethod
def get_instance(cls):
"""Get the singleton instance of the HeartModel."""
# If the instance doesn't exist, create it, clean the dataset, and train the model
if cls._instance is None:
cls._instance = cls()
cls._instance._clean()
cls._instance._train()
return cls._instance
def predict(self, disease):
"""Predict the probability of heart disease for an individual."""
# Convert the individual's features into a DataFrame
heart_df = pd.DataFrame(disease, index=[0])
# Convert gender values to binary (0 for Female, 1 for Male)
heart_df['sex'] = heart_df['sex'].apply(lambda x: 1 if x == 'Male' else 0)
# Predict the probability of heart disease using the logistic regression model
heart_attack = np.squeeze(self.model.predict_proba(heart_df))
return {'heart probability': heart_attack}
def feature_weights(self):
"""Get the feature importance weights from the decision tree model."""
# Extract feature importances from the decision tree model
importances = self.dt.feature_importances_
# Return feature importances as a dictionary
return {feature: importance for feature, importance in zip(self.features, importances)}
import json
import numpy as np
class HeartAPI:
class _Predict(Resource):
def post(self):
"""Handle POST requests."""
# Extract heart data from the POST request
patient = request.get_json()
# Get the singleton instance of the HeartModel
HeartModel_instance = HeartModel.get_instance()
# Predict the probability of heart disease for the individual
response = HeartModel_instance.predict(patient)
# Convert any numpy arrays to lists
for key, value in response.items():
if isinstance(value, np.ndarray):
response[key] = value.tolist()
# Return the prediction response as JSON
return jsonify(response)
# Add the _Predict resource to the heart_api with the '/predict' endpoint
api.add_resource(_Predict, '/predict')
if __name__ == "__main__":
# Create a Flask application
app = Flask(__name__)
# Register the heart_api blueprint with the Flask application
app.register_blueprint(heart_api)
# Run the application in debug mode if executed directly
app.run(debug=True)
In VSCode, show algorithmic conditions used to validate data on a POST condition.

In Postman, show URL request and Body requirements for GET, POST, and UPDATE methods.
GET method URL request:
For the GET function there does not need to be a body. API waits for GET request and once it recieves the request it sends data.
POST method URL request
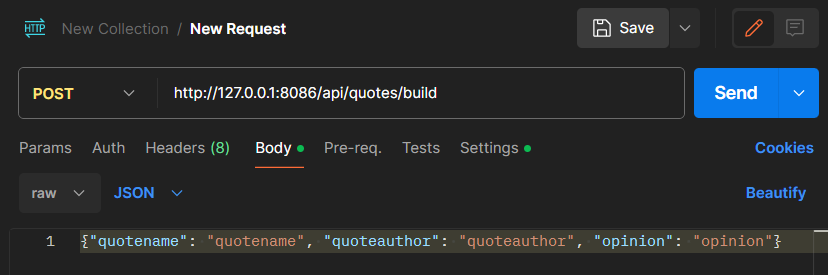
Post function requires the quotename (the quote itself), quoteauthor (author of the quote), and the opinion (your opinion/thoughts on the quote).
Update methods URL request:
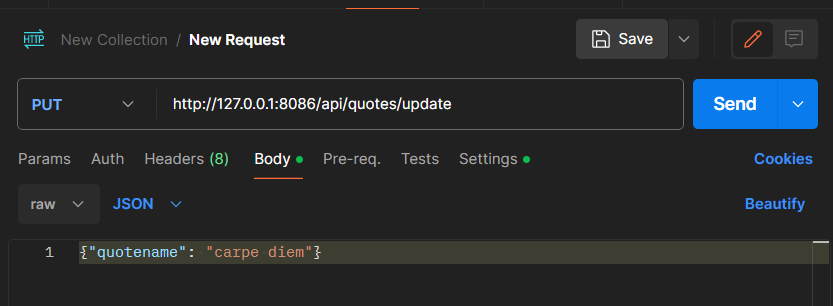
In Postman, show the JSON response data for 200 success conditions on GET, POST, and UPDATE methods.
JSON response for GET method
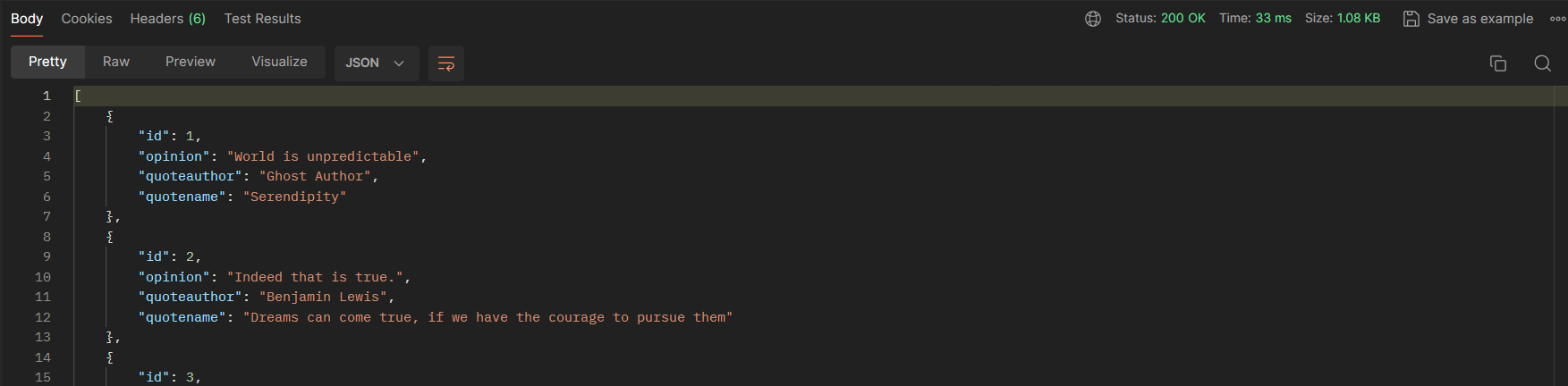
GET request is successful and JSON response displays the data from the quotes database in sqlite
JSON response for POST method
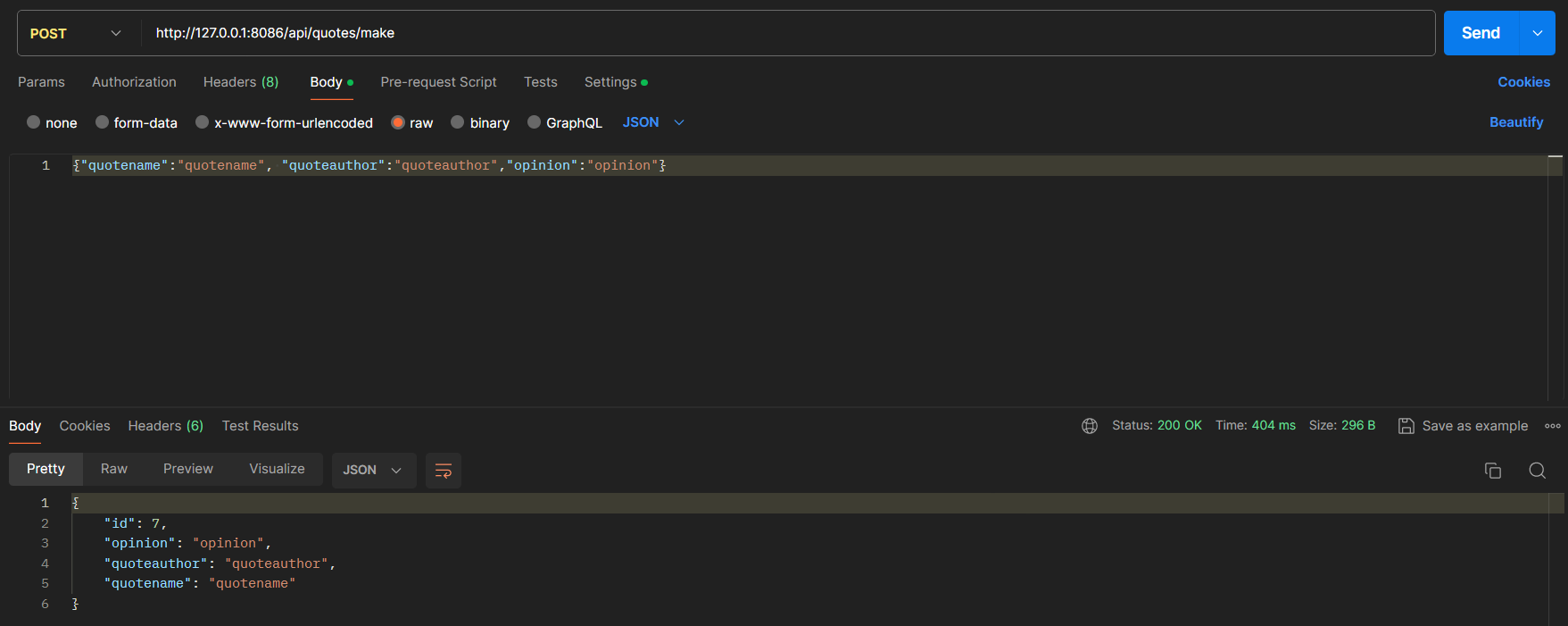
POST request is succesful and the new added quote is added into the database in
In Postman, show the JSON response for error for 400 when missing body on a POST request.
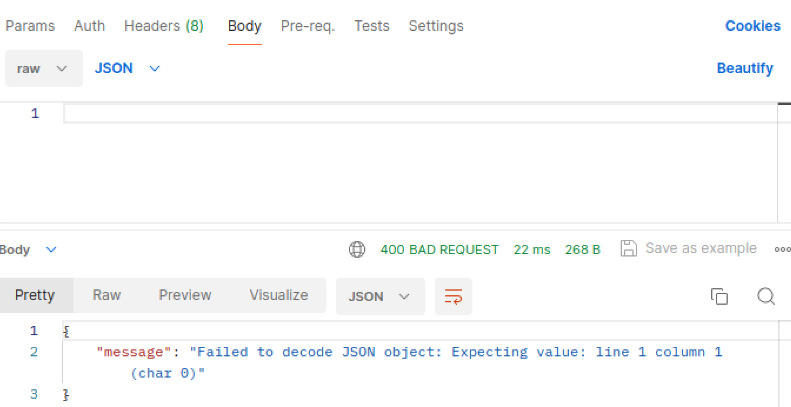
I cannot create a new database entry after not having a body for the POST request
Describe fetch and method that obtained the Array of JSON objects: I redirected my “view-quotes” button to fetch the array of JSON objects

Frontend
In Chrome inspect, show response of JSON objects from fetch of GET, POST, and UPDATE methods.
GET Response:
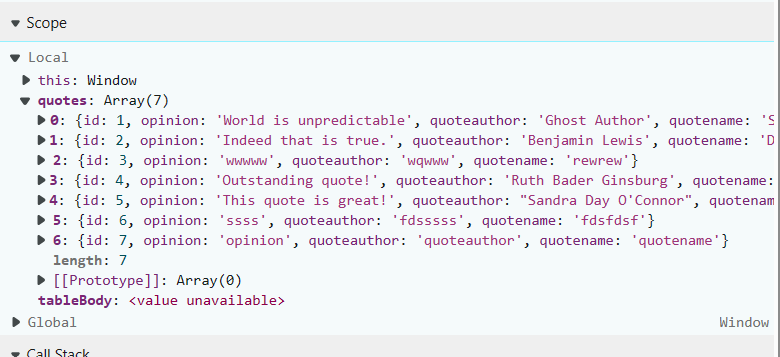 This is basically fetching the quote data from the backend JSON response in the frontend.
This is basically fetching the quote data from the backend JSON response in the frontend.
POST Response:
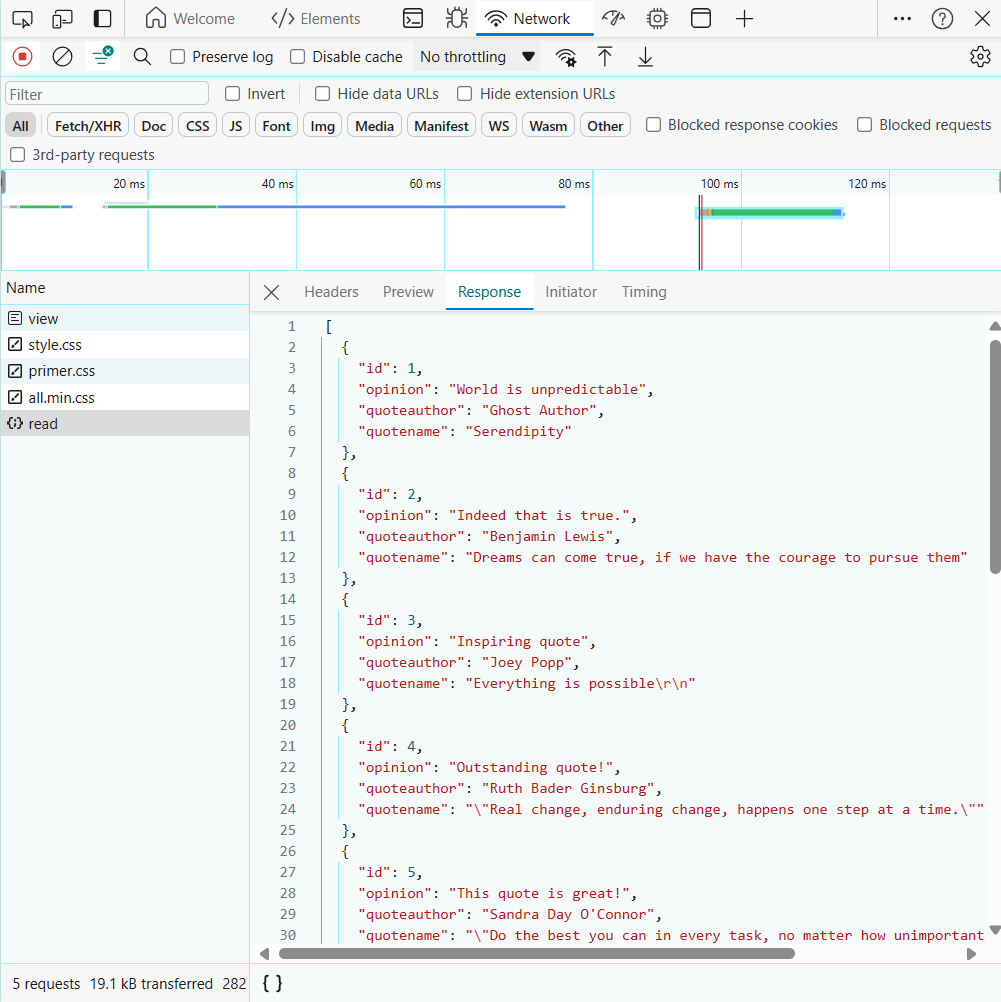
Table Output after using GET:
POST Response:
function fetchQuotes() {
fetch("http://127.0.0.1:8086/api/quotes/read")
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok.');
}
return response.json();
})
.then(data => {
renderQuotesTable(data);
})
.catch(error => {
console.error('Error fetching data:', error);
document.getElementById("quoteTable").innerHTML = "Error fetching quotes";
});
}
function renderQuotesTable(quotes) {
let tableBody = '';
quotes.forEach(quote => {
tableBody += `
<tr>
<td>${quote.quotename}</td>
<td>${quote.quoteauthor}</td>
<td>${quote.opinion}</td>
</tr>
`;
});
document.getElementById("quoteTable").innerHTML = tableBody;
}
Code on viewquotes button:
function fetchQuotes() {
let options = {
method: 'GET',
headers: {
'Content-Type': 'application/json;charset=utf-8'
},
};
fetch("http://127.0.0.1:8086/api/quotes/read", options)
.then(response => {
if (response.ok) {
return response.json();
} else {
throw new Error('Network response was not ok.');
}
})
.then(response => {
let dataContainer = document.getElementById("data");
dataContainer.innerHTML = "";
})
.catch(error => {
console.error('Error fetching data:', error);
document.getElementById("error").innerHTML = "Error fetching quotes";
});
}
Frontend Demo
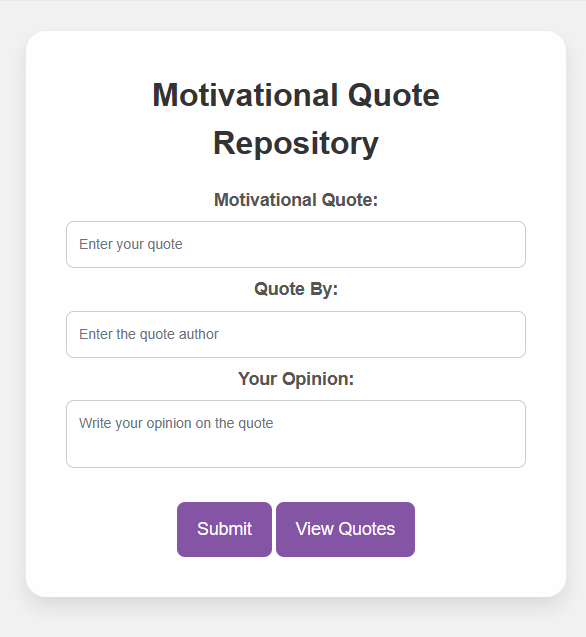
Design of the frontend that I styled using CSS and HTML
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Quote Repository</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f2f2f2;
margin: 0;
padding: 0;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
overflow: hidden;
}
.container {
background-color: rgba(255, 255, 255, 0.9);
padding: 40px;
border-radius: 20px;
box-shadow: 0 10px 20px rgba(0, 0, 0, 0.1);
max-width: 600px;
width: 90%;
text-align: center;
}
h1 {
font-size: 2.5rem;
margin-bottom: 20px;
color: #333;
}
h2 {
font-size: 2.0rem;
margin-bottom: 20px;
color: #333;
}
label {
font-weight: bold;
font-size: 1.1rem;
color: #555;
}
input[type="text"],
textarea {
width: 100%;
padding: 12px;
margin: 8px 0;
box-sizing: border-box;
border: 1px solid #ccc;
border-radius: 8px;
resize: none;
}
input[type="submit"] {
background-color: #8455a5;
color: white;
cursor: pointer;
padding: 14px 20px;
border: none;
border-radius: 8px;
font-size: 1.1rem;
transition: background-color 0.3s ease;
margin-right: 10px;
}
input[type="submit"]:hover {
background-color: #8455a5;
}
.error-message {
color: red;
margin-top: 5px;
}
#homeButton {
position: fixed;
top: 20px;
left: 20px;
font-size: 1rem;
text-decoration: none;
color: #333;
padding: 10px 15px;
border: 1px solid #ccc;
border-radius: 8px;
background-color: #f2f2f2;
z-index: 999;
}
#animation {
position: relative;
z-index: 1;
}
.background-animation {
position: absolute;
top: 0;
left: 50%;
transform: translateX(-50%);
width: 100%;
z-index: -1;
pointer-events: none;
opacity: 0.5;
}
/* Style for the "View Quotes" button */
.quotes-button {
background-color: #8455a5;
color: white;
cursor: pointer;
padding: 14px 20px;
border: none;
border-radius: 8px;
font-size: 1.1rem;
transition: background-color 0.3s ease;
margin-top: 20px;
}
.quotes-button:hover {
background-color: #684085;
}
</style>
</head>
This is me putting text into the input boxes (3 input boxes) filling out the Quote, the quote author and my opinion on the quote
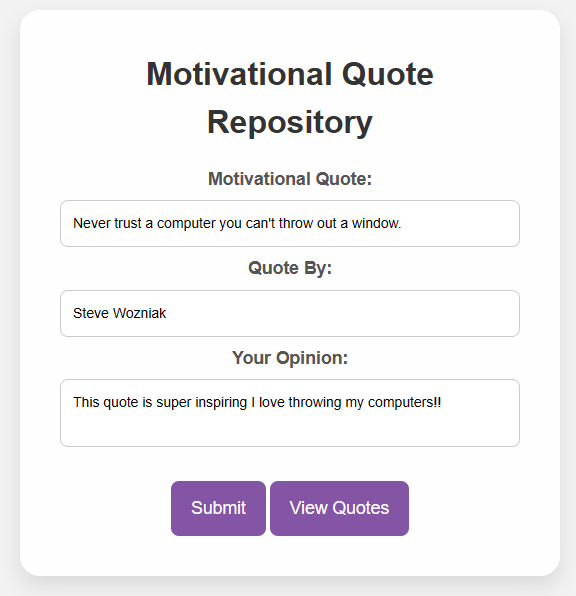
After I press the submit button, after putting in my input text, I get a response back saying that my quote has been succesfully submitted!
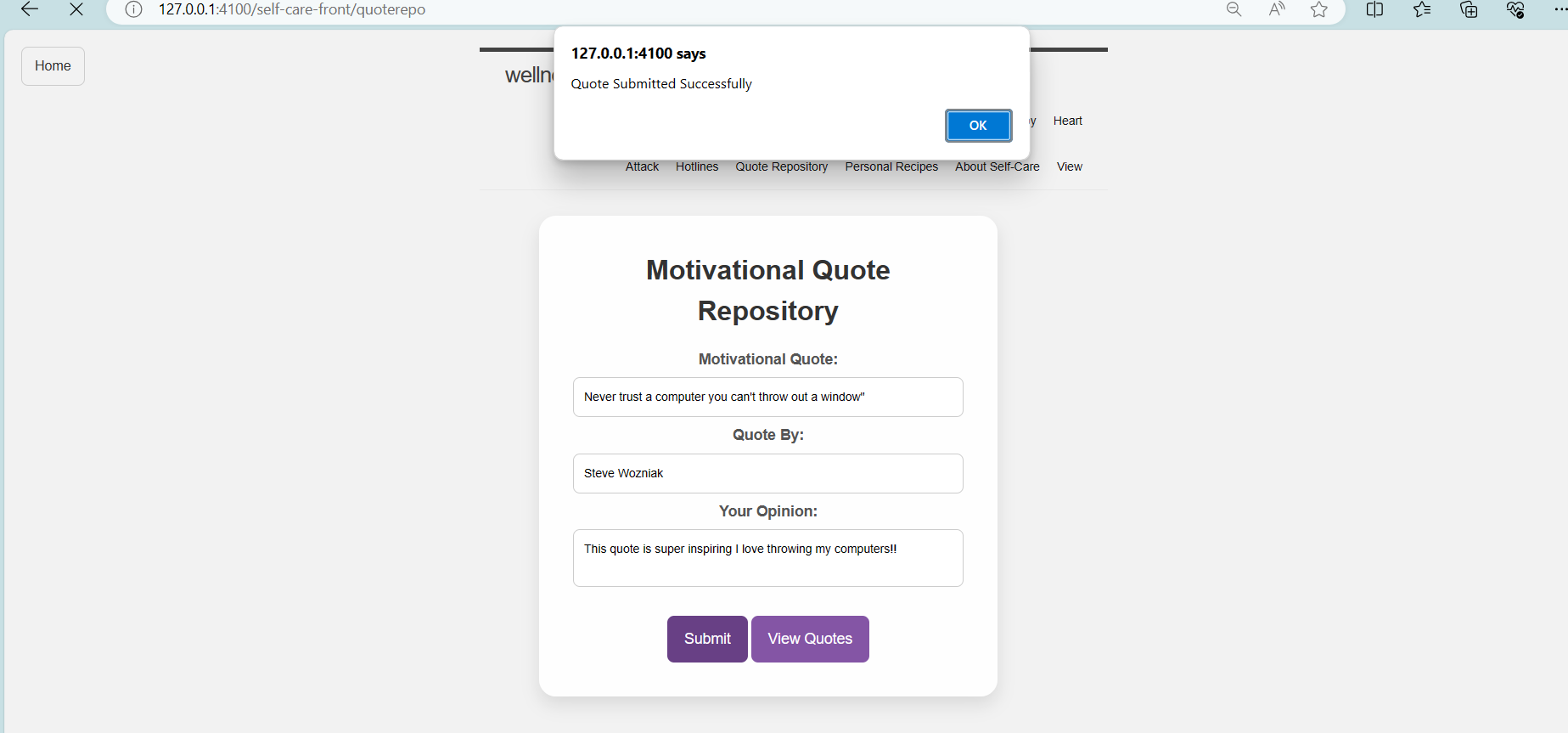
Now when I press my view quotes button I use the GET to get the updated sqlite database from the backend and display it in a table form on another external link which brings me to the view-quotes site of the page.
Code to GET your quotes from the updated sqlite database
function fetchQuotes() {
fetch("http://127.0.0.1:8086/api/quotes/read")
.then(response => {
if (response.ok) {
return response.json();
}
else {
console.error('Fetch response not ok');
throw new Error('Fetch response not ok');
}
})
.then(quotes_json_list => {
showQuotesTable(quotes_json_list);
})
.catch(error => {
console.error('Error fetching data:', error);
document.getElementById("quotes_list").innerHTML = "Error fetching quotes";
});
}
function showQuotesTable(quotes_json_list) {
let tblBody = '';
quotes_json_list.forEach(quote => {
tblBody += `
<tr>
<td>${quote.quotename}</td>
<td>${quote.quoteauthor}</td>
<td>${quote.opinion}</td>
</tr>
`;
});
document.getElementById("quotes_list").innerHTML = tblBody;
}
</script>
Response from the quote repository confirming your input
// Function to submit a new quote
function submitQuote() {
// Retrieving the values entered by the user for the quote, author, and opinion fields
let _quotename = document.getElementById('quotename').value;
let _quoteauthor = document.getElementById('quoteauthor').value;
let _opinion = document.getElementById('opinion').value;
// Checking if any of the fields are left empty
if (!_quotename || !_quoteauthor || !_opinion) {
// Alerting the user to fill in all the fields if any are left empty
alert("Please fill in all fields");
return; // Exiting the function early if any fields are empty
}
// Creating an object to store the submitted quote data
let quote_object = {
"quotename": _quotename,
"quoteauthor": _quoteauthor,
"opinion": _opinion,
};
// Sending a POST request to a server endpoint with the quote data
fetch('http://127.0.0.1:8086/api/quotes/make', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(quote_object) // Converting the JavaScript object to JSON format
})
.then(response => {
// Handling the response from the server
return response.json(); // Parsing the response as JSON
})
.then(response_json => {
// Displaying an alert to the user upon successful submission of the quote
alert("Quote Submitted Successfully");
})
.catch(error => {
// Handling any errors that occur during the submission process
alert("Quote Submission Failed. Please try again."); // Alerting the user about the error
});
}
If response from the backend flask is unseccuesful the code above with be run and it will inidicate that there was a failure in submitting the quote: Output is “Quote Submission Failed. Please try again.”
Algorithim Analysis
In the machine learning models that we created in class there is a ton of algorithim analysis. You prepare data and the predictions.
- The machine learning project that my team worked on was stroke and heart attack prediction. I worked on the heart attack prediction and made the frontend, model(backend), and API code (backend).
API code breakdown
Here in this part of the API code I am splitting the url of a kaggle database I downloaded as a .csv file and uploaded to google drive
I’m then cleaning the datasets and preparing them for training. I drop unecessary columns from the dataset and drop rows with the missing values.
from flask import Blueprint, jsonify, Flask, request
from flask_cors import CORS # Import CORS
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from flask_restful import Api, Resource
import numpy as np
import json
# Define a blueprint for the heart disease prediction API
heart_api = Blueprint('heart_api', __name__, url_prefix='/api/heart')
api = Api(heart_api)
CORS(heart_api)
class HeartModel:
"""A class representing the Heart Disease Prediction Model."""
# Singleton instance for HeartModel
_instance = None
def __init__(self):
"""Constructor method for HeartModel."""
self.model = None
self.dt = None
self.features = ['sex', 'age', 'cp', 'trtbps', 'chol', 'exng']
self.target = 'output'
# Load the heart disease dataset from a Google Drive link
url = 'https://drive.google.com/file/d/1kJcitXtlysIg1pCPQxV-lMSVTFsLWOkv/view'
url = 'https://drive.google.com/uc?id=' + url.split('/')[-2]
self.heart_data = pd.read_csv(url)
def _clean(self):
"""Clean the dataset and prepare it for training."""
# Drop unnecessary columns from the dataset
self.heart_data.drop(['fbs', 'restecg', 'thalachh', 'oldpeak'], axis=1, inplace=True)
# Drop rows with missing values
self.heart_data.dropna(inplace=True)
In this part of the code I am training the logistic regression and decision tree models. I am splitting that database into different X and Y and after initializing it, I am training the logistic regression model.
I also try and train the decision tree classifier as well. I am comparing two to see which one has the greater accuracy and was just playing around with the both of them.
def _train(self):
"""Train the logistic regression and decision tree models."""
# Split the dataset into features (X) and target (y)
X = self.heart_data[self.features]
y = self.heart_data[self.target]
# Initialize and train the logistic regression model
self.model = LogisticRegression(max_iter=1000)
self.model.fit(X, y)
# Initialize and train the decision tree classifier
self.dt = DecisionTreeClassifier()
self.dt.fit(X, y)
Here I am using the singleton instance of HeartModel and if the instance doesnt exist I am creating it. Then I use the predict function in order to predict the probability of the heart disease based on the inputs.
def predict(self, disease):
"""Predict the probability of heart disease for an individual."""
# Convert the individual's features into a DataFrame
heart_df = pd.DataFrame(disease, index=[0])
# Convert gender values to binary (0 for Female, 1 for Male)
heart_df['sex'] = heart_df['sex'].apply(lambda x: 1 if x == 'Male' else 0)
# Predict the probability of heart disease using the logistic regression model
heart_attack = np.squeeze(self.model.predict_proba(heart_df))
return {'heart probability': heart_attack}
Next, I’m getting feature importance weights from the decision tree model
def feature_weights(self):
"""Get the feature importance weights from the decision tree model."""
# Extract feature importances from the decision tree model
importances = self.dt.feature_importances_
# Return feature importances as a dictionary
return {feature: importance for feature, importance in zip(self.features, importances)}
import json
import numpy as np
In this final part of the API code– I am taking the input from the frontend side of the code (From the POST request) and I am predicting probability using the /predict
class HeartAPI:
class _Predict(Resource):
def post(self):
"""Handle POST requests."""
# Extract heart data from the POST request
patient = request.get_json()
# Get the singleton instance of the HeartModel
HeartModel_instance = HeartModel.get_instance()
# Predict the probability of heart disease for the individual
response = HeartModel_instance.predict(patient)
# Convert any numpy arrays to lists
for key, value in response.items():
if isinstance(value, np.ndarray):
response[key] = value.tolist()
# Return the prediction response as JSON
return jsonify(response)
# Add the _Predict resource to the heart_api with the '/predict' endpoint
api.add_resource(_Predict, '/predict')
if __name__ == "__main__":
# Create a Flask application
app = Flask(__name__)
# Register the heart_api blueprint with the Flask application
app.register_blueprint(heart_api)
# Run the application in debug mode if executed directly
app.run(debug=True)
Here is some of my code from the model (quotes.py) where I am seen to be training the logistic regression model. At the end the final model that I use for training is the decision tree classifier.
def _train(self):
"""Train the logistic regression, decision tree, and Gaussian Naive Bayes models."""
# Split the data into features and target
X = self.heart_data[self.features]
y = self.heart_data[self.target]
# Perform train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train the logistic regression model
self.model = LogisticRegression(max_iter=1000)
self.model.fit(X_train, y_train)
# Train a decision tree classifier
self.dt = DecisionTreeClassifier()
self.dt.fit(X_train, y_train)
# Train Gaussian Naive Bayes
self.gnb = GaussianNB()
self.gnb.fit(X_train, y_train)
My understanding of the algorithims I used
Linear Regression Algorithm:
- Like drawing the best-fitting straight line through data points on a graph.
- Used to predict the relationship between an independent variable (input) and a dependent variable (output).
How it works:
- Finds line that minimizes the distance between the actual data points and the predicted values on the line.
- Uses mathematical formulas to calculate the slope (weight) and intercept (bias) of the line.
Decision Tree Algorithm:
- Like flowcharts that help in decision-making based on features of data.
- Used to divide the data into smaller groups based on certain criteria to make predictions.
How it works:
- Starts at root node and splits the data into subsets based on the value of a feature.
- Continues the process recursively until it reaches a point where the subsets are pure (all have the same outcome) or a predefined stopping criterion is met.
- Each split is determined by selecting the feature that provides the best separation of data.
This venn diagram shows the pros and cons of each algorithim and their similarities:
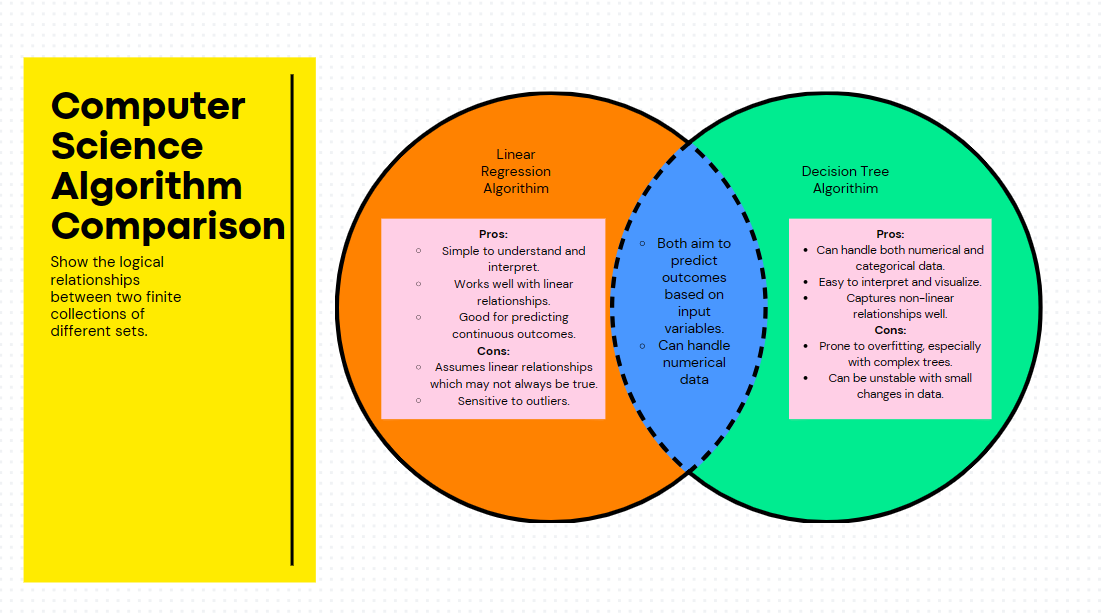
The decision tree model gave me higher accuracy and overall works with my dataset better therefore I used it.
Other notes
Deployment:
- use aws for deployment
- put everything into config.js – detect deployed or localhost link (uri optinos can be important from config.js)
- NGINX: creds, origin, methods should be changed –cors cookies
- remove cors code from main.py and _init.py
- @token_required used to be guarding certain API endpoints - returns current user whos accessing endpoint (defined in auth_middleware.py file) - cookie for global storage for uid - you dont need global backend variables - CRSF for additional security - Certbot is used in order to change from HTTP to HTTPS. - commands to make deployed website secure
- Tokens digital keys to access certain resources or services.
- They provide a way to authenticate and authorize users or applications. - Authentication: Verifying a user’s identity before granting access. - Authorization: Determining what actions a user can perform within a system.
other
- Model Code:
- Represents the logic and algorithms behind data analysis or predictions.
- Defines how data is processed to make predictions or decisions.
- API Code:
- Acts as a bridge between the model and external applications.
- Provides a way for other software to interact with the model and its functionalities.
- Benefits:
- Separation of Concerns: Model code focuses on data processing, while API code handles communication and interaction.
- Modularity: Allows for easier maintenance and updates to individual components.
College board guidelines
- have procedure or a function that you are calling
- define procedure name and return type
- contains one or more parameters that have an effect on the functionality of procedure -implements sequencing, iteration, and selection
-
function that you are calling must be called
- include list
- list being used such as in creating data (which I have in the quote repository)